RedisMod简介
首先介绍下RedisMod这个东西,它是一系列Redis的增强模块。有了RedisMod的支持,Redis的功能将变得非常强大。目前RedisMod中包含了如下增强模块:
RediSearch:一个功能齐全的搜索引擎;
RedisJSON:对JSON类型的原生支持;
RedisTimeSeries:时序数据库支持;
RedisGraph:图数据库支持;
RedisBloom:概率性数据的原生支持;
RedisGears:可编程的数据处理;
RedisAI:机器学习的实时模型管理和部署。
RediSearch + RedisJSON 比 Elasticsearch 更快 #https://mp.weixin.qq.com/s/-DqVroy6Qp30TulcmiRH0g
neuralredis:神经网络存储
rediscell:redis 4.0 以后开始支持扩展模块,redis-cell 是一个用rust语言编写的基于令牌桶算法的的限流模块,提供原子性的限流功能,并允许突发流量,可以很方便的应用于分布式环境中。
redisml:Redis-ML:机器学习模型服务器
https://blog.csdn.net/trouvailless/article/details/124272503
一、Redis布隆Bloom过滤器
https://cloud.tencent.com/developer/article/1464289
Redis布隆Bloom过滤器
Redis提供了三种强大数据结构:HyperLogLog,布隆过滤器和布谷鸟过滤器。本文讨论布隆过滤器:
布隆过滤器是最具代表性的概率数据结构,可用于各种应用,数据库,网络设备甚至加密货币都广泛使用布隆过滤器来加速内部操作。
客户端可以向服务查询某个数据是否已经被缓存了,Redis以名为ReBloom的模块方式提供,此数据结构允许你测试某个数据项是否属于一个大型集合的一分子,但无需将整个集合保存在内存中。
值得注意的是,你可以指定0%到100%之间的误报概率(不包括极值),并避免误报,关于布隆过滤器最重要的一点是布隆过滤器总是回复“可能是”或“绝对没有”。
使用ReBloom时,空间使用与目标错误率成反比。
此外,ReBloom支持增长过滤器,让你为每个过滤器动态分配内存,这对于没有“一条裤子适合所有人”的解决方案的情况非常有用(例如跟踪社会网络中的关系,这遵循幂律分布),虽然过滤器会自动增长,但为了确保最佳的空间和CPU效率,当你已经知道集合近似大小时,尽可能准确地分配过滤器空间非常重要。
适用情况:
1. 检查用户名可用性
2. 欺诈检测和缓解某些类型的网络攻击
3. 跟踪已知URL的Web爬虫
基本用法
加载ReBloom模块后,添加数据项时,redis将为你无缝创建到key:
BF.ADD -
如果要指定更多选项,可以使用:
BF.RESERVE
这将创建一个名为的过滤器,该过滤器最多可容纳项,目标错误率为。一旦溢出原始估计值,过滤器将自动增长。
不会重复抓取网址
假设你正在运行网络抓取工具,并且希望确保它每次都不会无限制地抓取已经抓取过的网址。
当你抓取一个域名网站,保存所有已知URL的列表可能不是问题,但是,如果该范围大小在接近Google规模之间的某种程度,你可能会浪费太多资源来更新和阅读这个列表(甚至可能不再适合放入内存)。
使用布隆过滤器可以解决同样的问题,例如:
BF.ADD crawled "redis.io/documentation"
要测试URL是否已被抓取,你可以使用:
BF.EXISTS crawled "redis.io/maybe-new-url"
回答将是:
0(绝对没有):这是一个新的URL,你可以抓取它; 要么
1(可能是):这很可能是一个已知的URL。
在积极的情况下,由你决定是否接受跳过某些URL并继续前进的可能性很小,或者在磁盘中中跟踪这些URL,这样你可以查询这些URL以获得精确的、尽管速度较慢的结果。
Bloom过滤器需要多少空间?
一个大小为100MB的过滤器可以容纳多达1亿个单独数据项,错误率为2%。
比特币还使用布隆过滤器优化客户端通信。
布隆不够时:布谷鸟Cuckoo过滤器
布隆过滤器是一种经过时间考验的惊人数据结构,可满足大多数需求,但它们并不完美,他们最大的缺点是无法删除项目,由于是一种数据存储在过滤器内的方式,一旦添加了项目,就无法将其与其他数据项完全分开,在不引入新的错误的前提下几乎无法删除。
Cuckoo过滤器提供更新的概率数据结构,它以不同方式存储信息,导致性能特征略有不同,并且能够在需要时删除项目。
布谷鸟过滤器在下面情况比布隆过滤器更好:
1. 删除项目
2. 更快的查找(因为更好的内存位置)
3. 空间效率(当目标错误率低于3%时)
4. 更快的插入(当过滤器的填充率低于80%时)
在以下情况下,布谷鸟过滤器比布隆过滤器更糟糕:
1. 你的填充率超过80%;在这种情况下,布谷鸟过滤器的插入速度很快就会低于布隆。
2. 你有更宽松的目标错误率(大于3%),使布谷鸟过滤器的空间效率降低
3. 你需要高度可预测的行为(因为布谷鸟过滤器在插入过程中使用随机源来提供性能改进)
基本用法:
Cuckoo过滤器也存在于Redis的ReBloom中,可以像使用Bloom一样使用,唯一的区别是命令前缀是CF而不是BF,并且你有一个新的删除命令:
CF.DEL
-
其他所有内容都可以使用与布隆过滤器相同的方式建模。
结论
概率数据结构优雅地解决了许多类型的问题,否则,这些问题需要更多的计算能力、成本和开发工作,在本文中,我们介绍了三种有用的概率数据结构:
1. HyperLogLog(包含在Redis中)来计算集合中的元素。
2. 布隆过滤器(在ReBloom中可用),用于跟踪集合中存在或缺失的元素。
3. Cuckoo过滤器(ReBloom中提供)可以像布隆一样跟踪元素,但具有从集合中删除元素的附加功能。
二、ReJSON:将Redis作为JSON存储
ReJSON本身应该使任何Redis用户都对JSON感到高兴。该模块提供了一种新的数据类型,该数据类型是为快速高效地处理JSON文档而量身定制的。像任何Redis数据类型一样,ReJSON的值存储在键中,这些键可通过专门的命令子集进行访问。这些命令或模块公开的API旨在使从JSON世界进入Redis的用户直观易懂,反之亦然。考虑以下示例,该示例显示了如何设置和获取值:
127.0.0.1:6379> JSON.SET scalar . '"Hello JSON!"'
127.0.0.1:6379> JSON.SET object . '{"foo": "bar", "ans": 42}'
127.0.0.1:6379> JSON.GET object
"{\"foo\":\"bar",\"ans\":42}"
127.0.0.1:6379> JSON.GET object .ans
"42"
127.0.0.1:6379>
像任何行为良好的模块一样,ReJSON的命令带有前缀。双方JSON.SET并JSON.GET期望键的名称作为其第一个参数。在第一行中,我们将.名为scalar的键的根(由句点字符:表示 )设置为字符串值。接下来,为另一个名为key的对象设置一个JSON对象(首先读取整个对象),然后按路径设置一个子元素。
实际情况是,每当你调用时JSON.SET,该模块就会通过流式词法分析器获取值,该词法分析器将解析输入的JSON并从中构建树数据结构:
ReJSON将数据以二进制格式存储在树的节点中,并支持JSONPath的子集,以方便引用子元素。它拥有针对每个JSON值类型量身定制的原子命令库,包括 JSON.STRAPPEND用于追加字符串, JSON.NUMMULTBY用于乘以数字以及JSON.ARRTRIM用于修剪数组……并使海盗满意的工具。
由于ReJSON是作为Redis模块实现的,因此可以将其与任何支持以下功能的Redis客户端一起使用:支持模块(不支持ATM)或允许发送原始命令(最支持ATM)。例如,你可以通过redis-py从Python代码中使用启用了ReJSON的Redis服务器,如下所示:
import redis
import json
data = {
'foo': 'bar',
'ans': 42
}
r = redis.StrictRedis()
r.execute_command('JSON.SET', 'object', '.', json.dumps(data))
reply = json.loads(r.execute_command('JSON.GET', 'object'))
但这仅仅是其中的一半。ReJSON不仅是一个漂亮的API,而且在性能方面也很强大。初始性能基准已经证明,例如:
上图比较了对具有三个嵌套级别的3.4KB JSON有效负载执行的读取操作和写入操作的速率(操作/秒)和平均延迟。ReJSON与将数据存储在String中的两个变体相对应。两种变体均实现为Redis服务器端Lua脚本,并且该json.lua 变体存储原始的序列化JSON,并 msgpack.lua 使用MessagePack编码。
从GitHub存储库中获取它或在线阅读文档。我们仍然要添加许多功能,但是它确实很整洁。如果你有功能要求或发现问题,请随时使用存储库的问题跟踪器
三、RediSearch基于Redis的高性能全文搜索引擎
https://ningyu1.github.io/site/post/74-redisearch/
最近在参考CQRS DDD架构来进行公司的库存中心重构设计,在CQRS架构中需要一个in-memory的方式快速修改库存在通过消息驱动异步更新到DB,也就是说内存的数据是最新的,DB的数据是异步持久化的,在某一个时刻内存和DB的数据是存在不一致的,但是满足最终一致性。
这样我们就需要内存当作前置DB在使用,因此不单纯的只满足修改数据,还需要满足Query的要求,内存结构的数据Query是比较麻烦的,它不像DB那样已经实现好了索引检索,需要我们自己来设计Key的机构和搜索索引的构建。
当然行业里也有这样的做法,对数据修改的时候双写到内存(Redis)和ElasticSearch再异步到DB,这样Query全部走向ElasticSearch,但是我觉得这样做的复杂度会增加很多,所以就在看如何基于Redis来设计一个搜索引擎。
看到了RedisLabs团队开发的基于Redis的搜索引擎:RediSearch
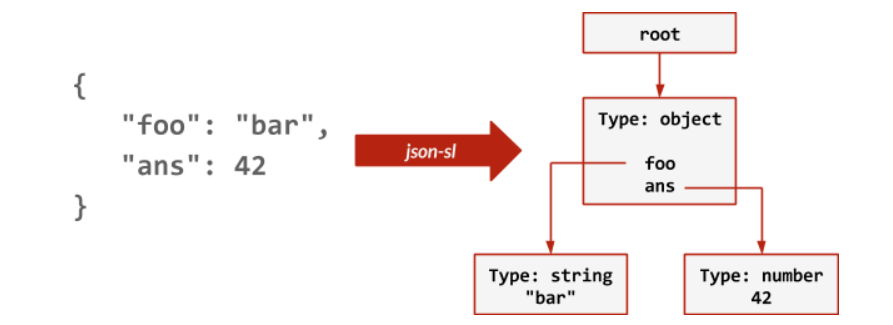 ReJSON将数据以二进制格式存储在树的节点中,并支持JSONPath的子集,以方便引用子元素。它拥有针对每个JSON值类型量身定制的原子命令库,包括 JSON.STRAPPEND用于追加字符串, JSON.NUMMULTBY用于乘以数字以及JSON.ARRTRIM用于修剪数组……并使海盗满意的工具。
由于ReJSON是作为Redis模块实现的,因此可以将其与任何支持以下功能的Redis客户端一起使用:支持模块(不支持ATM)或允许发送原始命令(最支持ATM)。例如,你可以通过redis-py从Python代码中使用启用了ReJSON的Redis服务器,如下所示:
import redis
import json
data = {
'foo': 'bar',
'ans': 42
}
r = redis.StrictRedis()
r.execute_command('JSON.SET', 'object', '.', json.dumps(data))
reply = json.loads(r.execute_command('JSON.GET', 'object'))
但这仅仅是其中的一半。ReJSON不仅是一个漂亮的API,而且在性能方面也很强大。初始性能基准已经证明,例如:
ReJSON将数据以二进制格式存储在树的节点中,并支持JSONPath的子集,以方便引用子元素。它拥有针对每个JSON值类型量身定制的原子命令库,包括 JSON.STRAPPEND用于追加字符串, JSON.NUMMULTBY用于乘以数字以及JSON.ARRTRIM用于修剪数组……并使海盗满意的工具。
由于ReJSON是作为Redis模块实现的,因此可以将其与任何支持以下功能的Redis客户端一起使用:支持模块(不支持ATM)或允许发送原始命令(最支持ATM)。例如,你可以通过redis-py从Python代码中使用启用了ReJSON的Redis服务器,如下所示:
import redis
import json
data = {
'foo': 'bar',
'ans': 42
}
r = redis.StrictRedis()
r.execute_command('JSON.SET', 'object', '.', json.dumps(data))
reply = json.loads(r.execute_command('JSON.GET', 'object'))
但这仅仅是其中的一半。ReJSON不仅是一个漂亮的API,而且在性能方面也很强大。初始性能基准已经证明,例如:
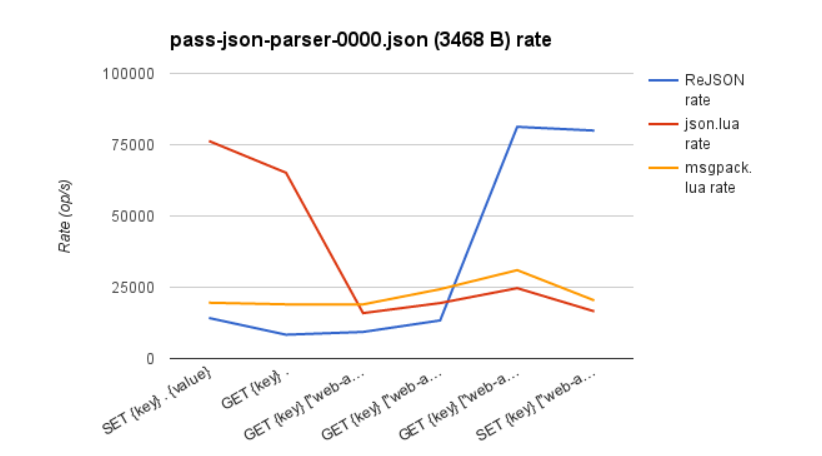
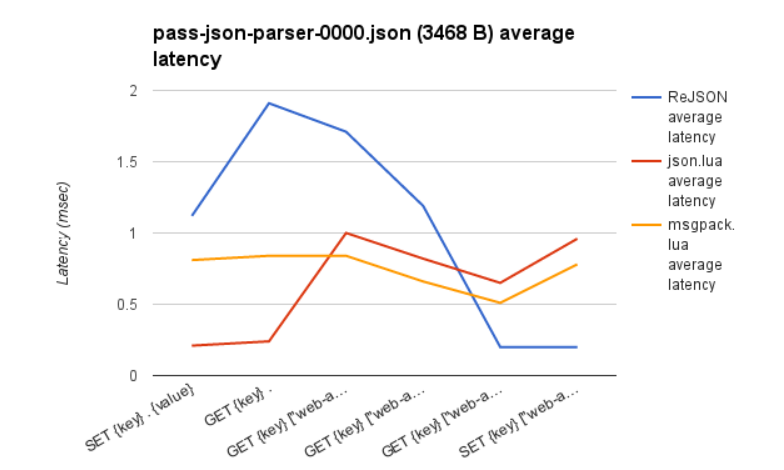 上图比较了对具有三个嵌套级别的3.4KB JSON有效负载执行的读取操作和写入操作的速率(操作/秒)和平均延迟。ReJSON与将数据存储在String中的两个变体相对应。两种变体均实现为Redis服务器端Lua脚本,并且该json.lua 变体存储原始的序列化JSON,并 msgpack.lua 使用MessagePack编码。
从GitHub存储库中获取它或在线阅读文档。我们仍然要添加许多功能,但是它确实很整洁。如果你有功能要求或发现问题,请随时使用存储库的问题跟踪器
上图比较了对具有三个嵌套级别的3.4KB JSON有效负载执行的读取操作和写入操作的速率(操作/秒)和平均延迟。ReJSON与将数据存储在String中的两个变体相对应。两种变体均实现为Redis服务器端Lua脚本,并且该json.lua 变体存储原始的序列化JSON,并 msgpack.lua 使用MessagePack编码。
从GitHub存储库中获取它或在线阅读文档。我们仍然要添加许多功能,但是它确实很整洁。如果你有功能要求或发现问题,请随时使用存储库的问题跟踪器